Why federated learning is important
A paradox lies at the heart of health technology policy. On one hand we’d like to make the most of data, and this entails sharing it across many stakeholders. But on the other hand health data is extremely sensitive and there are justifiable cries for privacy. The coronavirus pandemic has thrust this tension into the public discourse, and we struggle to find the appropriate policies for data sharing, immunity passports, and contact tracing.
But what if we can sidestep this paradox altogether? What if we could learn from massive amounts of data without needing to share that data?
Federated learning allows us do precisely this and that is why I’m so excited about it. In this article I hope to explain in lay terms what federated learning is, lay out different federated learning initiatives in healthcare today, and make the argument for why I think federated learning is important.
What is federated learning?
Federated learning is a way of training machine learning algorithms. It allows for a network of participants to collaboratively train an algorithm without any participant needing to share their data. Instead of sending data to a centralized repository, federated learning works by “sending the algorithm” to the data stored in its home location. Participants in the network are sent this algorithm and they each improve it by training it on their data locally, thus creating an updated algorithm.
This updated algorithm, and not the underlying data, is what is shared. Each participant in the network starts with the same algorithm (the “global model”) and after training on their local data ends up with a slightly updated version (a “local model”). All of the updated algorithms are sent to a “coordinator” which aggregates them together into a single algorithm (an updated “global model”), which is then sent to participants once more for further training.
Origins and an example from auto-correct
In all likelihood you have benefited from and contributed to a federated learning network without ever knowing it. Federated learning originated from a team at Google, who developed it as a way to improve typing suggestions on-device.
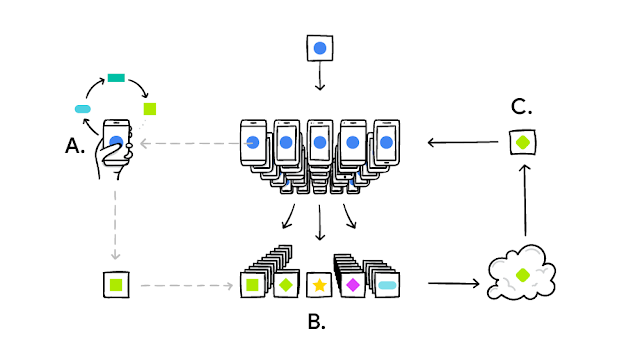
The above diagram, taken from Google’s blog, shows the federated learning life cycle across a network of smart phones. These are the steps:
-
A: An algorithm (the blue circle) is distributed to smart phones, which updates it based off of what users type (into the green square)
-
B: Many users’ updates are aggregated together
-
C: These updates form the basis of a new algorithm, which is distributed and the process repeats
Using federated learning enables three core benefits: privacy is preserved, auto-correct is improved, and predictions can be made almost instantly as each phone has the auto-correct algorithm on their devices, which means it’s not necessary to beam data to the cloud and back to get a prediction. Apple recently revealed their usage of federated learning to train it’s voice assistant, Siri, in a similar way with similar benefits.
Where does blockchain technology fit?
In the example of auto-correct the storage of data and training of algorithms is decentralized, but the decision about what algorithm is trained and what data it is trained on is centralized. Google unilaterally makes these choices for their auto-correct network. Smart phone users might be fine with that, but if a federated learning network is training on more sensitive data, say health data or a pharma company’s competitive molecular data, then centralizing control is not tenable.
Blockchains are a potential answer. They provide a way for networks to decentralize control over what to train and equip participants with data access management tools. In networks that use a blockchain, algorithms are only trained after going through some pre-specified decision making process that happens on chain. Moreover participants can use smart contracts to specify what datasets are available for training (and make some datasets offlimits by omission). All actions of the federated learning network are recorded transparently and immutably on a blockchain, thus creating an audit trail. This is useful because participants can be sure their policies are being respected and that no secret actions have taken place.
Furthermore, as I’ll discuss in the “limitations” section, there is a need for reproducibility in federated learning networks, particularly in healthcare. The audit trail also gives a list of actions that could be taken to reproduce an algorithm created in a federated learning network. Lastly, a blockchain can be used to record the contributions of each party in a network and compensate them, thus incentivizing collaboration.
Federated learning in healthcare
To date we’ve mostly capitalized on health data by aggregating massive amounts of data in central locations, thus exposing that data to newfound privacy risks by creating huge “honey pots” that are enticing to bad actors. Moreover, the need to share data creates a disincentive for healthcare organizations, as they are wary of losing control and are keen to protect their patients’ privacy. At it’s worst these dynamics manifest themselves in well connected insiders getting exclusive sweetheart data deals and in massive and murky markets for deidentified health data.
But there is a better way. Federated learning can help us realize this promise without compromising on privacy, and several marque institutions have made strides towards this:
-
Mayo Clinic’s Clinical Data Analytics Platform uses federated learning and is offering insights derived from its data. Their early focus is on pharma.
-
Penn Medicine and Intel Labs are leading a federation of 29 (!) organizations in 7 countries to use federated learning in identifying brain tumors.
-
King’s College London’s AI Centre for Value Based Healthcare (AI4VHB) connects universities, hospitals, and industry across the UK in a federated learning network. They plan to tackle a wide range of issues.
-
A group of German oncology centers of excellence are using federated learning to study cancer
-
Stanford Medicine, Ohio State University, the American College of Radiology, a Brazilian imaging center, Partners HealthCare, and NVIDIA found that federated learning outperformed siloed analysis in mammogram assessment algorithms
-
MELLODDY is a group of 10 global pharmaceutical companies using federated learning to accelerate drug discovery
-
Owkin, Substra, and a group of French hospitals and academic labs formed a federated learning called HealthChain after receiving a grant
-
Owkin convened a federated learning consortium examining COVID-19 and cardiovascular complications, with other directions to come. They are open sourcing their algorithms!
The pace is picking up too, many of these initiatives were announced in 2020.
By eliminating the need to share data to make it useful federated learning enables collaboration where it wasn’t possible before. More partners, and partners of different types, can come together when unburdened by privacy concerns. Notably a few networks today are international, which is only possible because the laws requiring health data be stored within the country aren’t a problem if you aren’t sharing data. We can expect that the total amount of data federated in these networks will be much greater than what could have been aggregated in the status quo. This is important because more data and data from different populations leads to better algorithms, and ultimately better health outcomes.
Limitations and future areas of exploration
Make no mistake federated learning is no panacea. There are several key challenges and limitations, and I’ll review some of them here.
The first challenge to note is that algorithms may contain some of the information used to train them. In other words it is sometimes possible to take an algorithm and reverse engineer it to yield some of the data used to train that algorithm. Obviously this is a bad thing if you’re training algorithms on sensitive data. There is a whole field, differential privacy, dedicated to minimizing this risk and often times additional privacy preserving measures are necessary to mitigate this class of risk.
Another key challenge is that of governance and incentives. Federated learning is a tool for collaboration, but organizations may not want to collaborate. Organizations can, perhaps justifiably, feel that their competitors will benefit from a collaboration more than they would. Furthermore, there needs to be clear rules as to how algorithms created from networks are owned and can be used. These rules are tricky to create as some parties’ contributions to an algorithm might have been greater than others, and those contributions are not always something you can figure out beforehand. Novel business models and incentive mechanisms are needed to address this challenge generally.
The third challenge I want to highlight relates to reproducibility. To see how this is a challenge consider reproducibility for algorithms in the status quo. On my computer I have data and a file that I can use to train an algorithm on that data. If I were to find some insight with this algorithm I could share my data and file with others, who could use them to reproduce my insight independently. In a federated learning network this is, by definition, not possible as data is not being shared. As I laid out above blockchains can help, but this is an unresolved and active area of active research.
Lastly, in order to collaboratively train an algorithm all parties in a federated learning network need to have their data in the same format. Much has been written on the topic of standards in healthcare elsewhere and I won’t repeat that here. I will note that it is not an intractable issue, but it is notoriously difficult to deal with.
Conclusion
Health data is inherently sensitive, and thus demanding of privacy. Yet at the same time health data is inherently statistical, and thus holds within it insights that could improve health for all. The promise of federated learning is to unlock these insights without compromising on privacy. Moreover, federated learning will enable us to assemble more data than ever in federated networks, leading to better algorithms and ultimately better outcomes.
Further still, technologies like federated learning disprove the premise that we must share data to benefit from it. In doing so federated learning challenges us to radically rethink the way that we approach data creation, sharing, analysis, and monetization. I hope to address these aspects in future blog posts.